Merhaba arkadaşlar.
Bu makale konusunda sizlere son dönemlerde popülerleşmekte olan yüksek performanslı dağıtık mesajlaşma sistemi Apache Kafka’nın, genel hatlarına değiniyor olacağım.
Distributed messaging system konusuna girmeden önce, her şeyin temeli olan big data olayına biraz değinelim. Günümüz teknolojisinde big data denilen şey, git gide hızla büyümeye ve her an oluşabilen bir hale gelmiştir. En basit örnek olarak Google üzerinde bizler her saniye yeni veriler oluşturmaktayız. İstatistiklere göre sadece Google üzerinde anlık 40.000 civarında arama sonuçları oluşmaktadır. Buda günlük olarak yaklaşık 3.4 civarına ve yıllık olarak ise 1.2 trillion search verisi yapmaktadır.
Bu verilerin anlık olarak devasa boyutlara ulaşmasıyla beraber ise, real-time’a yakın bir sürede geri ulaşılabilme ihtiyaçları doğmuştur. İşte bu noktada Apache Kafka‘nın temel önemi, big data akışını düşük bir latency ile sağlamaya çalışmasıdır. Bu proje ilk başta LinkedIn bünyesinde geliştirilip, sonrasında ise open-source bir hale gelmiştir. Apache Kafka düşük latency oranı ile real-time veri akışını sağlayabilmek için verileri log kaydına benzer bir yapıda tutarak, farklı sistemlere MQ(Messaging Queue) şeklinde sunmaktadır. Dilerseniz Kafka terminolojisine biraz giriş yapalım.
Kafka’nın genel terminolojisine baktıktan sonra, dilerseniz Topic konusunu biraz açalım.
Kafka’da message’ların tutulduğu yerin, topic’ler olduğunu söylemiştik. Bu topic’ler bir veya birden fazla partition’lardan yani bölümlerden meydana gelirler. Message’lar ise partition’lara yukarıdaki şekilde de görülebileceği üzere sıralı ve immutable olarak eklenirler. Topic’ler içerisindeki bu message’lar, unique olarak belirlenir ve her bir sıraya offset adı verilir. Topic’lere gelen her bir message, yukarıda şekilde olduğu gibi dizi sonuna sıralı bir şekilde ekleniyor ve offset numarası sırasıyla artıyor. Ekleme işlemi ise immutable olarak gerçekleştiği için ilgili message’ın partition ve offset bilgisi değişmiyor. Bu işlem sayesinde istenilen message, herhangi bir okuma işleminden sonra bile kaybolmuyor, tekrar erişebilmek mümkün oluyor.
Kafka’nın distributed tarafındaki harika bir özelliği ise her bir client, ayrı bir bölüme yazabilir veya ayrı bir bölüm üzerinden okuma işlemini gerçekleştirebilmektedir. Kafka’nın bu partitioning mimarisi sayesinde paralel okuyabilme ve yazabilme işlemleri de mümkün olabilmektedir.
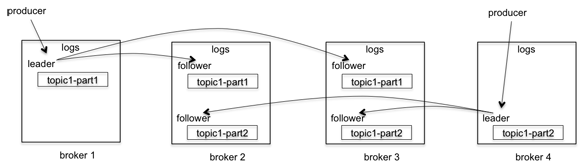
Her bir bölüm cluster’daki diğer broker’lara, istenildiği taktirde yedekleme için kopyalanabilirler. Yukarıda görselde olduğu gibi her bir bölümün, bir leader’ı olur ve diğerleri(follower) bu leader’ı takip ederler. Dışarıdan okuma yazma işlemleri de sadece leader bölüme yapılır. Ayrıca leader, gelen tüm yazma işlemlerini sıraya koymakla ve bu yazma işlemlerini diğer replica’lara(followers) aynı sırayla yaymakla sorumludur. Failure durumu için ise bir broker’da herhangi bir bölüm hata verirse, o bölümün diğer follower’larından birisi leader haline gelir ve hizmet vermeye devam eder.
Topic’lere message gönderenlerin de, Producer’lar olduğunu söylemiştik. Producer’lar hangi message’in hangi bölüme gideceğine karar verebilirler. Bu karar verme işlemini bir scheduling algoritması olan round-robin şeklinde veya semantic partitioning ile gerçekleştirir.
Örneğin bir message gönderilirken message key verilmiş ise gönderilen bu message, message key’e göre ilgili topic’in semantic partitioning bölümüne yazılmaktadır. Yani istediğimiz message’ları aynı partition içerisine göndermek istediğimizde kullanabiliriz.
Kafka, içerisinde Message Queue ve Publish-Subscribe olmak üzere iki model barındırır. Queue modelinde consumer’lar server’dan tek tek okumaktadır ve her bir kayıt bu consumer’lardan birisine gitmektedir. Publish-Subscribe modelinde ise kayıtlar, tüm consumer’lara broadcast olmaktadır.
Bu iki modelin güçlü yanlarının olduğu gibi zayıf yanları da mevcuttur:
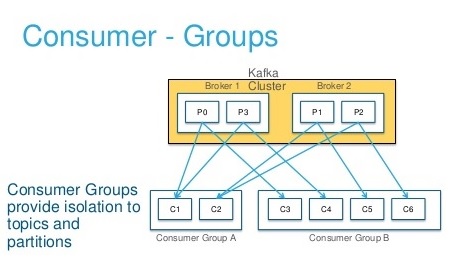
Yukarıda şekilde görüldüğü gibi her bir consumer, bir consumer group’a aittir. Bunlara ek olarak group içerisindeki consumer sayısı bölüm sayısından fazla olsa bile, kafka en fazla bölüm sayısı kadar bir group içerisindeki consumer’ın okumasına izin vermektedir.
ve web activity tracking işlemlerinde güçlü bir şekilde kullanılabilmektedir.
Kimler kullanıyor kısmına baktığımızda ise tabi ilk olarak LinkedIn, Yahoo, Twitter, Netflix, Spotify, Uber, PayPal ve Foursquare gibi büyük verilere sahip olan firmalar karşımıza çıkmaktadır.
Apache Kafka konusunda değineceklerim şimdilik bu kadar. Apache Kafka’nın kurulumu ve örnek kullanımı hakkındaki konuları ise bir sonraki makale serisinde ele almayı planlıyorum.
Umarım keyifli bir giriş bilgisi olmuştur.
Takipte kalın.
http://www.forbes.com/sites/bernardmarr/2015/09/30/big-data-20-mind-boggling-facts-everyone-must-read/#703040d6c1d3
https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
https://www.infoq.com/articles/apache-kafka
{:en}In today’s technological age, we typically build our application solutions on event-driven architecture in order…
{:tr} Makalenin ilk bölümünde, Software Supply Chain güvenliğinin öneminden ve containerized uygulamaların güvenlik risklerini azaltabilmek…
{:tr}Bildiğimiz gibi modern yazılım geliştirme ortamında containerization'ın benimsenmesi, uygulamaların oluşturulma ve dağıtılma şekillerini oldukça değiştirdi.…
{:tr}Bildiğimiz gibi bir ürün geliştirirken olabildiğince farklı cloud çözümlerinden faydalanmak, harcanacak zaman ve karmaşıklığın yanı…
{:tr}Bazen bazı senaryolar vardır karmaşıklığını veya eksi yanlarını bildiğimiz halde implemente etmekten kaçamadığımız veya implemente…
{:tr}Bildiğimiz gibi microservice architecture'ına adapte olmanın bir çok artı noktası olduğu gibi, maalesef getirdiği bazı…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Aydınlatıcı bir yazı olmuş, teşekkürler.